近端策略优化算法(PPO)视频内容总结
近端策略优化算法(Proximal Policy Optimization, PPO)是一种高效的强化学习算法,也是 OpenAI 训练 ChatGPT 时使用的关键算法之一。以下是对该算法介绍视频的详细总结:
1. 核心思想:从“同策略”到“异策略”的突破
视频首先剖析了传统策略梯度(Policy Gradient)方法的核心缺陷,以此凸显 PPO 的创新价值:
- 传统方法的“同策略”(On-Policy)局限:用于训练的(采样)策略和正在优化的(目标)策略必须完全一致。
-
“同策略”引发的两大问题:
-
采样效率极低:采集到的数据仅能用于更新一次参数,更新后需彻底丢弃,无法重复利用,导致数据资源严重浪费。
- 训练稳定性差、方差高:每次参数更新都依赖全新样本,样本分布的随机性会直接导致训练过程波动剧烈,收敛过程不稳定。
PPO 的核心改进:转向“异策略”(Off-Policy)
- 打破“采样”与“学习”的强绑定,将数据采样和策略优化两个过程分离。
- 允许重复使用过去采集的历史数据进行训练(即“数据复用”),不仅大幅提升采样效率,还能通过多轮数据平滑训练波动,增强收敛稳定性。
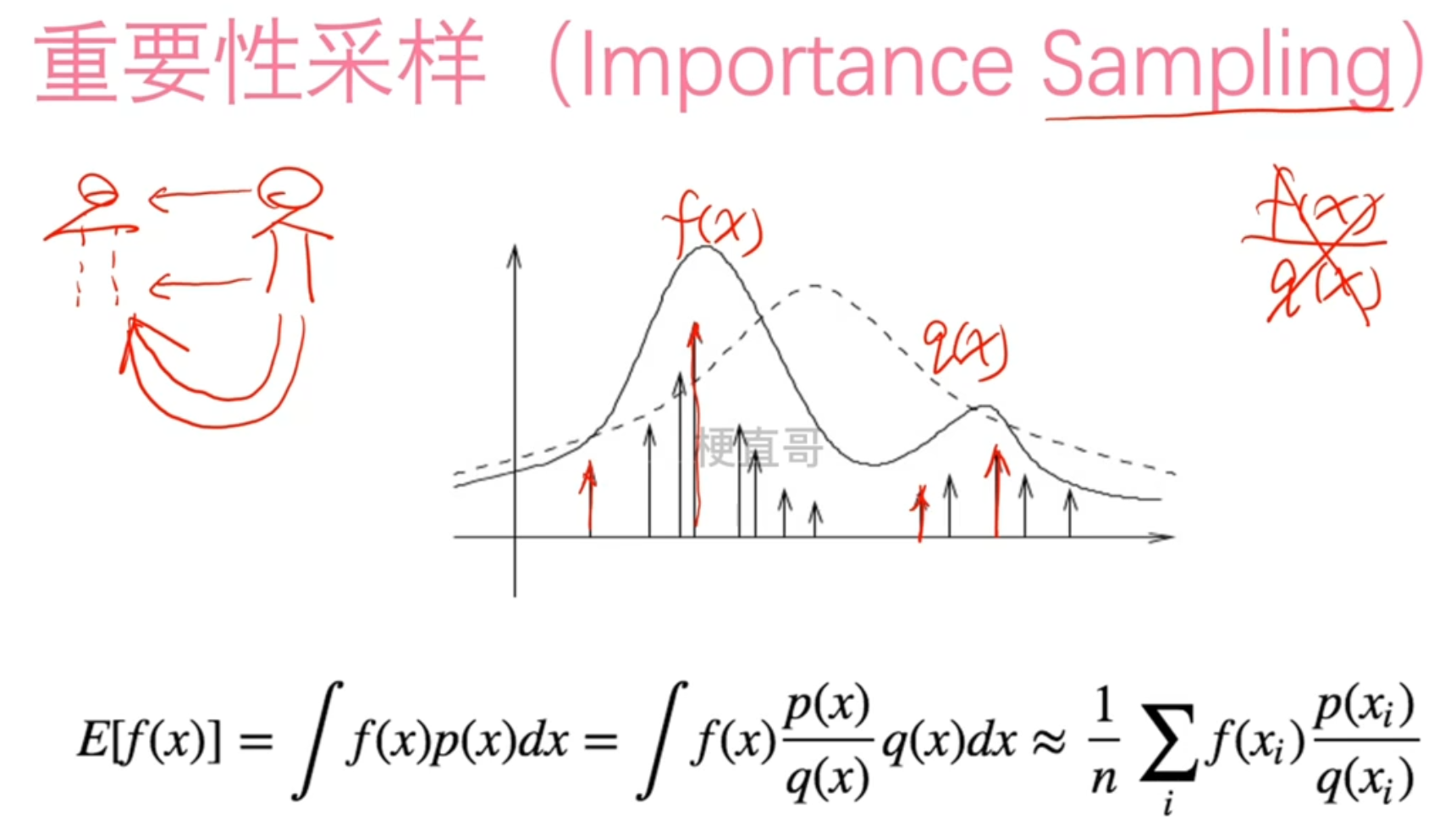
2. 关键技术:重要性采样(Importance Sampling)
要实现“异策略”学习,核心难题是:如何用旧策略(采样策略 \(\pi_{\theta'}\))收集的数据,来评估和优化新策略(目标策略 \(\pi_{\theta}\))?视频指出,重要性采样是解决这一问题的关键技术:
- 本质是一种统计修正方法,通过引入概率比值(权重) \(\frac{\pi_{\theta}(a|s)}{\pi_{\theta'}(a|s)}\),修正新旧策略在“状态 \(s\) 下选择动作 \(a\)”的概率差异。
- 该比值可视为“修正因子”:它能将旧策略采集数据的分布,调整为近似新策略的数据分布,从而让旧数据可用于评估新策略的性能,为策略更新提供有效方向。
3. PPO 的目标函数与两大核心改进
单纯的重要性采样存在稳定性隐患:若新旧策略差异过大,概率比值可能出现极端值(过大或过小),导致训练崩溃。PPO 通过两种核心改进(对应两种主流变体)解决这一问题,核心目标均为“限制新策略的更新幅度,避免其偏离旧策略过远” (这也是“近端”Proximal 的核心含义)。
改进一:自适应惩罚(PPO-Penalty)
- 核心思路:在目标函数中加入“惩罚项”,通过量化新旧策略的相似度来控制更新幅度,相似度用KL 散度(Kullback-Leibler Divergence)衡量(KL 散度越小,策略越相似)。
- 目标函数公式:\(J_{PPO}(\theta) = J^{\theta'}(\theta) - \beta KL(\theta, \theta')\)
其中,\(J^{\theta'}(\theta)\) 是基于重要性采样的原始目标函数,\(\beta\) 是惩罚系数,\(KL(\theta, \theta')\) 是新旧策略的 KL 散度。 - 自适应机制:惩罚系数 \(\beta\) 动态调整——若 KL 散度超过预设最大值(说明策略偏离过大),则增大 \(\beta\) 加强惩罚;若 KL 散度过小(说明更新过慢),则减小 \(\beta\) 降低惩罚。
改进二:裁剪(PPO-Clip)——更常用的主流版本
- 核心思路:不依赖 KL 散度,直接对“概率比值”进行“裁剪(Clip)”,强制将其限制在一个小区间内,从根源上避免极端值导致的更新失控。
-
目标函数设计:计算两个值,取其中较小值作为最终优化目标,确保更新幅度可控:
-
原始值:概率比值 \(r_t\) × 优势函数 \(A_t\)(\(r_t = \frac{\pi_{\theta}(a_t|s_t)}{\pi_{\theta'}(a_t|s_t)}\),\(A_t\) 表示“状态 \(s_t\) 下选择动作 \(a_t\) 比平均动作好多少”)。
- 裁剪值:\(clip(r_t, 1-\epsilon, 1+\epsilon)\) × 优势函数 \(A_t\)(\(\epsilon\) 是预设的裁剪阈值,通常取 0.1 或 0.2,即限制 \(r_t\) 在 [0.8, 1.2] 或 [0.9, 1.1] 区间内)。
- 效果:即使优势函数 \(A_t\) 较大(某动作收益极高),裁剪后的概率比值也不会过度放大更新幅度,从而保证训练过程稳定。
4. 算法步骤(PPO-Clip)与适用条件
算法步骤(PPO-Clip 流程)
- 初始化:设定初始策略参数 \(\theta\)、裁剪阈值 \(\epsilon\)(如 0.2)、优化器(常用 Adam)等超参数。
- 循环迭代训练:
a. 数据采集:使用当前策略 \(\pi_k\)(第 k 轮策略)与环境交互,收集一批数据(包含状态 \(s\)、动作 \(a\)、奖励 \(r\)、下一状态 \(s'\) 等)。
b. 优势估计:基于采集的数据,计算每个时间步的优势函数 \(\hat{A}^k\)(常用时序差分 TD 或广义优势估计 GAE 方法)。
c. 策略更新:在收集到的固定数据上,使用优化器多次迭代优化(通常 3-10 轮),最大化 PPO-Clip 的裁剪目标函数,更新策略参数 \(\theta\),得到新策略 \(\pi_{k+1}\)。
d. 重复循环:以新策略 \(\pi_{k+1}\) 再次采集数据,进入下一轮训练,直至策略性能收敛。
适用条件
- 高维度连续动作空间任务:如机器人关节控制、自动驾驶车辆的油门/转向控制等(传统算法在这类任务中易出现维度灾难,PPO 效率更高)。
- 对收敛稳定性要求高的场景:如大规模强化学习训练、工业级控制任务,PPO 的裁剪机制能有效避免训练崩溃。
- 大规模分布式训练:支持采样过程(多智能体并行与环境交互)和训练过程(多线程优化参数)分离,可充分利用分布式算力加速训练。
综上,PPO 通过重要性采样实现了高效的“异策略”数据复用,再通过裁剪(Clip) 核心技巧解决了更新稳定性问题,最终成为当前最流行、最稳健的强化学习算法之一,广泛应用于自然语言处理、机器人控制、游戏 AI 等领域。
您是否想进一步了解 PPO 的具体实现细节(如优势函数计算、代码框架),或其在特定领域的应用案例?