强化学习之“策略梯度(Policy Gradient)”核心思想与原理总结
本内容基于相关视频梳理,系统讲解策略梯度方法的核心逻辑、优化方向及算法流程,帮助理解其从理论到实践的关键脉络。
1. 核心思想:从“基于价值”到“基于策略”
视频首先通过对比两种强化学习核心范式,明确策略梯度的定位与优势:
- 基于价值(Value-Based)的方法(如 Q-Learning):
先学习价值函数(如 \(Q(s, a)\),表示“在状态\(s\)下执行动作\(a\)的价值”),再通过argmax 等规则从价值函数中推导策略(选择价值最大的动作)。
局限性:在连续动作空间或高维动作空间中,对价值函数的建模和“选最大动作”的操作难度极高,易陷入计算瓶颈。 - 基于策略(Policy-Based)的方法(策略梯度属于此类):
不依赖价值函数,直接学习参数化策略 \(\pi_{\theta}(a|s)\)——通常以神经网络为载体,输入状态\(s\),输出动作\(a\)的概率分布(如连续动作空间输出均值和方差,离散动作空间输出各动作概率)。
核心目标:通过梯度上升(Gradient Ascent) 调整参数\(\theta\),找到能使总奖励期望最大化的策略。
策略梯度的主要优点
- 建模效率高:直接对策略建模,无需推导价值函数,特别适配连续动作空间(如机器人关节控制、自动驾驶油门/转向调节)。
- 探索性更好:策略输出概率分布,而非确定动作,天然具备探索能力(如以一定概率选择非最优动作,避免陷入局部最优)。
- 收敛性更优:在部分复杂场景中,策略梯度的收敛稳定性优于基于价值的方法。
2. 目标函数与策略梯度定理
策略梯度是无环境模型(Model-Free) 的方法(无需预先知道环境状态转移规则),其核心数学基础围绕“目标函数”与“梯度推导”展开:
目标函数 \(J(\theta)\)
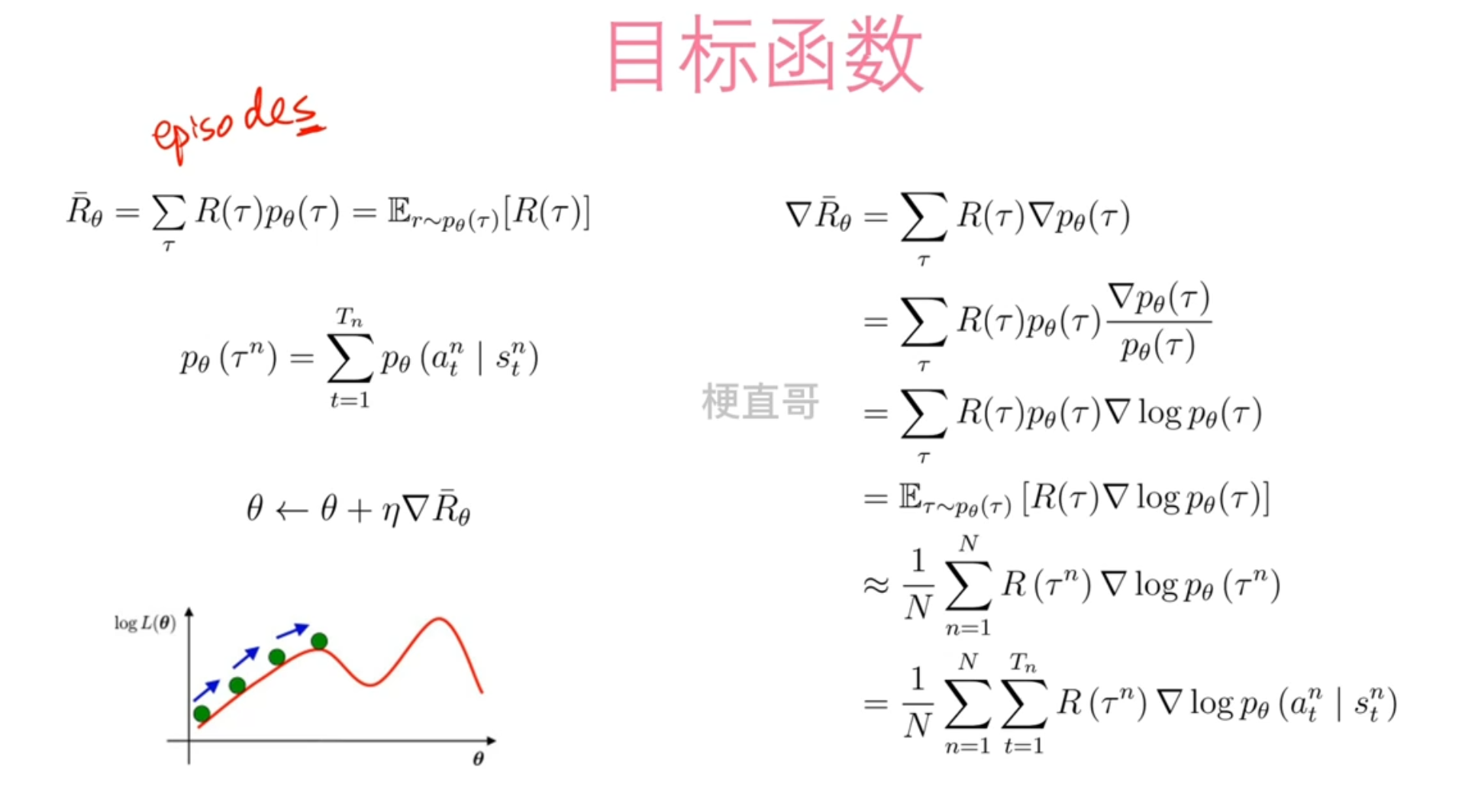
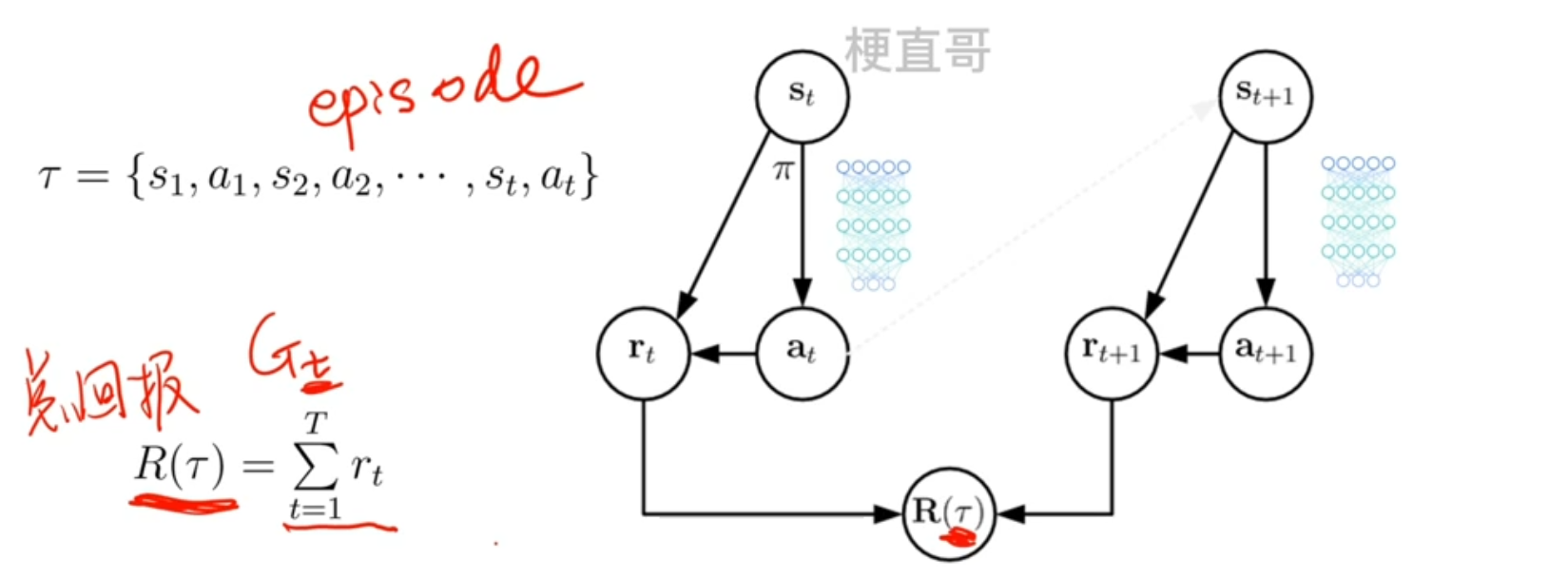
优化目标是最大化轨迹(episode, \(\tau\) )的期望总奖励 \(\bar{R}_{\theta}\),公式定义为:
\(J(\theta) = E_{\tau \sim p_{\theta}(\tau)}[R(\tau)]\)
其中:
- \(\tau = (s_1, a_1, r_1, s_2, a_2, r_2, ..., s_T, a_T, r_T)\) 表示一条完整轨迹(从初始状态到终止状态);
- \(p_{\theta}(\tau)\) 是参数为\(\theta\)的策略下,轨迹\(\tau\)发生的概率;
- \(R(\tau) = \sum_{t=1}^T r_t\) 是轨迹\(\tau\)的总奖励(\(r_t\)为\(t\)时刻的即时奖励)。
策略梯度定理
核心是推导目标函数\(J(\theta)\)对参数\(\theta\)的梯度\(\nabla_{\theta} J(\theta)\),视频中重点讲解了关键的“对数导数技巧(log-derivative trick)”,最终得到梯度公式:
\(\nabla_{\theta} J(\theta) = E_{\tau \sim p_{\theta}(\tau)}[R(\tau) \nabla_{\theta} \log p_{\theta}(\tau)]\)
在实践中,由于期望无法直接计算,需通过蒙特卡洛采样(即运行\(N\)次试验,收集\(N\)条轨迹)来近似估计这个期望。
3. 关键改进(解决高方差问题)
基础策略梯度算法(如 REINFORCE)存在高方差(High Variance) 问题——每次采样的梯度波动大,导致训练不稳定。视频介绍了两种核心改进方案:
改进一:引入基线(Baseline)
- 问题根源:若用整条轨迹的总奖励\(R(\tau)\)更新策略,会导致“只要\(R(\tau)\)为正,所有动作的概率都会被提升”,但实际中部分动作可能只是“平均水平”,不应被强化。
-
解决方案:从总奖励中减去一个基线(Baseline)\(b\),得到优势函数(Advantage Function) \(\hat{A}\):
\(\hat{A} = R(\tau) - b\) -
若\(\hat{A} > 0\):动作效果优于平均水平,提升其概率;
- 若\(\hat{A} < 0\):动作效果劣于平均水平,降低其概率。
- 核心优势:基线\(b\)的引入不改变梯度期望(因\(E[\nabla_{\theta} \log p_{\theta}(\tau) \cdot b] = 0\)),但能大幅降低梯度方差,让训练更稳定。
实践中,基线\(b\)通常设置为状态价值函数\(V(s)\)(表示“在状态\(s\)下的期望总奖励”)。
改进二:功劳分配(Credit Assignment)
- 问题根源:用整条轨迹的总奖励\(R(\tau)\)计算\(t\)时刻动作的梯度时,会让\(t\)时刻的动作“为\(t\)时刻之前的奖励负责”,不符合逻辑(例如游戏中“当前步骤的操作”不应影响“之前已获得的分数”)。
- 解决方案:将\(R(\tau)\)替换为未来累计折扣奖励(Reward-to-Go) ,只计算从\(t\)时刻到轨迹结束的奖励总和:
\(R_t = \sum_{t'=t}^{T} \gamma^{t'-t} r_{t'}\)
其中\(\gamma\)为折扣因子(\(0 < \gamma \leq 1\)),用于降低远期奖励的权重(符合“近期奖励更重要”的直觉)。 - 核心优势:让梯度计算更贴合“动作仅对后续奖励负责”的逻辑,进一步降低方差。
4. 算法步骤(Vanilla Policy Gradient)
“Vanilla Policy Gradient(VPG,基础策略梯度)”是 Sutton 在 1999 年提出的经典算法,整合了上述改进,具体步骤如下:
-
初始化:
-
策略网络\(\pi_{\theta}\)(如全连接神经网络,参数为\(\theta\));
- 基线\(b\)(初始可设为常数,后续逐步优化为状态价值函数\(V(s)\))。
- 循环迭代(直至收敛) :
a. 收集数据:用当前策略\(\pi_{\theta}\)与环境交互,收集一批轨迹(如\(N\)条完整episode)。
b. 计算回报:对每条轨迹的每个时刻\(t\),计算“未来累计折扣奖励”\(R_t\)(即Reward-to-Go)。
c. 计算优势:对每个时刻\(t\),计算优势函数\(\hat{A}_t = R_t - b(s_t)\)(\(s_t\)为\(t\)时刻的状态)。
d. 更新基线:通过最小化损失\(\|b(s_t) - R_t\|^2\)(均方误差),拟合基线\(b\),使其尽可能接近\(R_t\)(本质是将\(b\)优化为状态价值函数\(V(s)\))。
e. 更新策略:用梯度上升更新策略参数\(\theta\),梯度的近似计算基于采样数据:
\(\nabla_{\theta} J(\theta) \approx \frac{1}{N} \sum_{每条轨迹} \sum_{t=1}^T \nabla_{\theta} \log \pi_{\theta}(a_t|s_t) \hat{A}_t\)
最终参数更新公式:\(\theta \leftarrow \theta + \eta \nabla_{\theta} J(\theta)\)(\(\eta\)为学习率)。
5. 适用条件
策略梯度方法在以下场景中表现突出,是优先选择的算法之一:
- 连续动作空间:如机器人关节角度控制、自动驾驶的油门/刹车力度调节(基于价值的方法难以处理此类高维连续动作)。
- 高维状态空间:如输入为图像的游戏(如Atari游戏)、无人机导航的视觉观测(策略网络可直接从高维输入中提取特征,无需手动设计状态表示)。
- 需要参数化策略的场景:如需要输出动作概率分布、保证探索性的任务(如博弈类问题,需平衡“探索”与“利用”)。
总结
策略梯度的核心是“直接优化策略参数\(\theta\),最大化期望总奖励”,通过引入基线和功劳分配(Reward-to-Go) 解决了基础算法的高方差问题,最终形成稳定高效的VPG算法。它弥补了基于价值方法在连续动作空间的短板,是强化学习中处理复杂决策问题的重要技术,也是后续更先进算法(如PPO、A2C)的基础。